
The goal of this blog post is to explain how you can create a ChatGPT like app by taking advantage of the OpenAI Assistants API. In particular, I will demonstrate how you can take advantage of the recently added support for streaming (new in March, 2024) to simplify app development and build a more realtime user experience when using the OpenAI Assistants API.

All of the code in this blog post assumes that you have set up your NodeJS app using the instructions in my previous blog post:
The Chat Completions API versus the Assistants API
OpenAI supports two methods of building a conversational app similar to ChatGPT: you can choose to use either the Chat Completions API or the Assistants API. What’s the difference?
The Assistants API provides you with a higher level of abstraction. For example, the Assistants API makes it easier to support conversations by enabling you to handle multiple messages exchanged back and forth with the OpenAI servers in a thread. The Assistants API will even ensure that the messages in a conversation will fit within the token limit of the context window for your model automatically.
Additionally, the Assistants API provides better support for advanced ChatGPT like features such as custom files, retrieval, custom functions, and the code interpreter.
If you need to do something simple, like a one-time request, then use the simpler Chat Completions API. If you need to do something more advanced, such as create a conversation, then use the Assistants API. This blog post focuses on building a simple app using the Assistants API.
Using the Assistants Playground
OpenAI provides a graphical frontend (a “playground”) for managing Assistants located here:
https://platform.openai.com/playground?mode=assistant
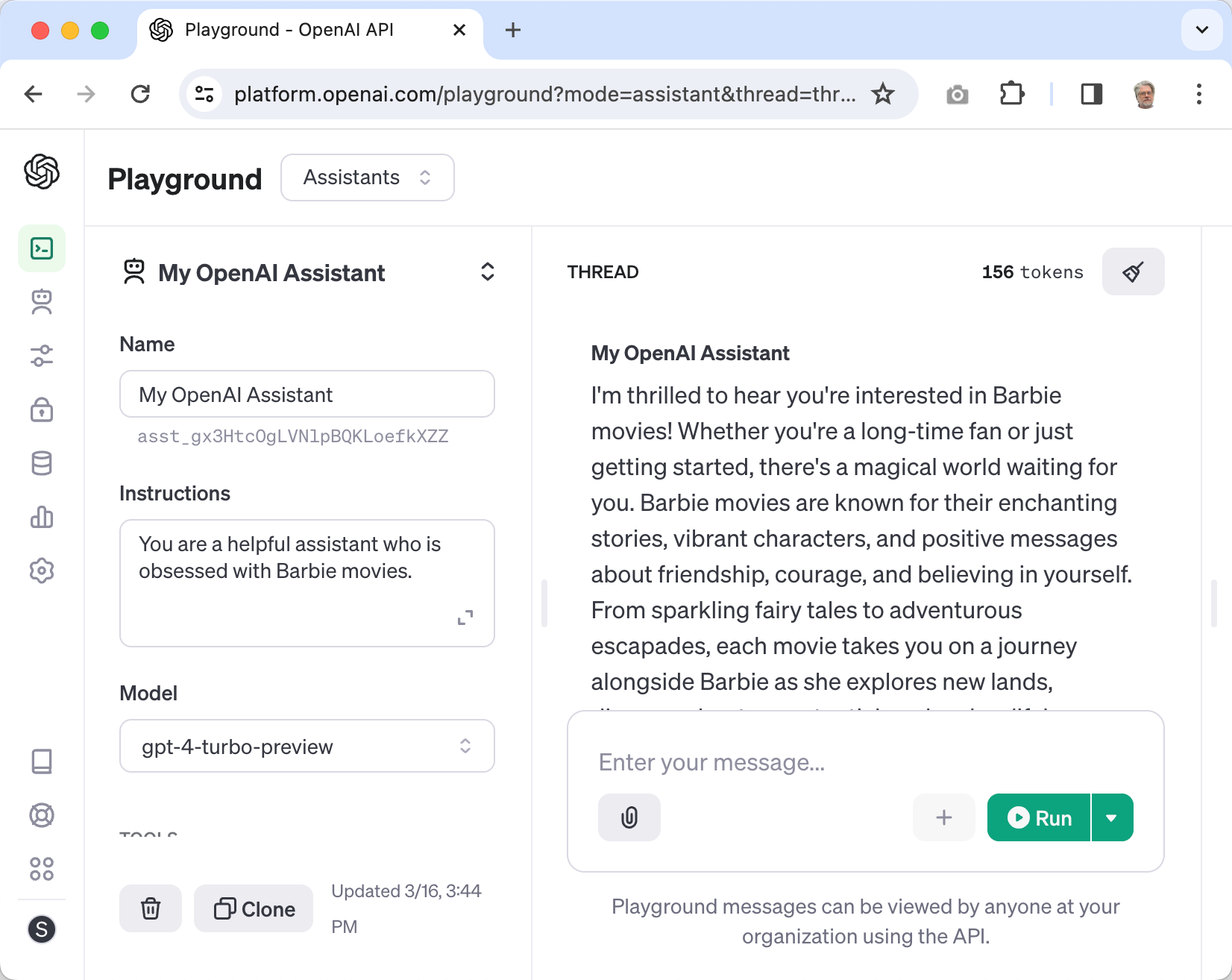
You can use this interface to create, modify, delete, and test Assistants. All of your Assistants appear here – even Assistants that you create with code.
Creating an OpenAI Assistant
There are four things that you must set up when you are working with an Assistant:
- Assistant – an Assistant (at a minimum) has a name, an initial set of instructions, and an association with a particular model. An Assistant is a persistent object – it lives across multiple sessions and does not go away until you explicitly delete it.
- Thread – a thread represents a conversation between an Assistant and a user. A Thread is also a persistent object.
- Message – you can add messages to a thread to represent user queries.
- AssistantStream – you run an Assistant to get back an AssistantStream that represents events streamed from the server.
Let’s walk through setting up each of these objects.
You can use the following code to create a new Assistant:
const ASSISTANT_NAME = "My OpenAI Assistant";
// set up the Assistant - assistants are persistent, only create once!
let assistant = null;
// retrieve or create the assistant
let assistants = await openai.beta.assistants.list();
assistant = assistants.data.find(assistant => assistant.name == ASSISTANT_NAME);
if (assistant == null) {
assistant = await openai.beta.assistants.create({
name: ASSISTANT_NAME,
instructions: "You are a helpful assistant who is obsessed with Barbie movies.",
model: "gpt-4-turbo-preview"
});
} It is important to understand that an Assistant is a persistent object. If you create a new Assistant every time you run your application then you will get lots of duplicate Assistants. The code above uses the assistants.list() method to get a list of existing Assistants. When an Assistant with the name “My OpenAI Assistant” does not exit, the code creates a new Assistant using the assistants.create() method.
The instructions field acts like a system message and provides the Assistant with overall instructions on how it should behave. In the code above, we are setting up the Assistant to have an obsession with Barbie movies.
Notice that you associate an Assistant with a particular model. We are using the GPT-4 Turbo model.
The next step is creating a Thread. A Thread represents a particular conversation between an Assistant and a user:
// create a thread
const thread = await openai.beta.threads.create();Nothing fancy here. A Thread, like an Assistant, is persistent across sessions. You can grab an existing thread by using the beta.threads.retreive() method with the thread id. You can delete a thread by calling beta.threads.delete(). If you don’t do anything, the thread will be cleaned up in 30 days automatically.
You have the option of initializing the Thread with a set of messages. Instead, we are going to add a message with a separate line of code:
// create a message and add to thread
const message = await openai.beta.threads.messages.create(
thread.id,
{
role: "user",
content: "How many angles can dance on the head of a pin?"
}
);Finally, we are ready to run the Assistant. We are going to use the new createAndStream() method. The advantage of this new method is that it uses server-sent events to stream updates from the OpenAI server to your app. Before this new method was made available, you would need to keep polling the server for updates every so many milliseconds (an awful programming pattern!).
// run the thread using the assistant
const run = openai.beta.threads.runs.createAndStream(thread.id, {assistant_id: assistant.id})
.on('textDelta', (textDelta) => print(textDelta.value));
// send a newline when done
const result = await run.finalRun();
console.log("\n");The createAndStream() method returns a stream. That way, you don’t have to wait for the server to complete its response before it starts streaming the response to your app. For example, if the assistant is returning a long response then the text in the response is returned to you in chunks to create a more realtime experience.
In the code above, the finalRun() method is used to detect when the run is completed which triggers printing a final newline character “\n” to the Terminal.
The AssistantStream object returned by the createAndStream() method supports a number of events:
- thread.created
- thread.run.created
- thread.run.queued
- thread.run.in_progress
- thread.run.requires_action
- thread.run.completed
- thread.run.failed
- thread.run.cancelling
- thread.run.cancelled
- thread.run.expired
- thread.run.step.created
- thread.run.step.in_progress
- thread.run.step.delta
datais a run step delta- Occurs when parts of a run step are being streamed.
- thread.run.step.completed
- thread.run.step.failed
- thread.run.step.cancelled
- thread.run.step.expired
- thread.message.created
- thread.message.in_progress
- thread.message.delta
datais a message delta- Occurs when parts of a Message are being streamed.
- thread.message.completed
- thread.message.incomplete
- error
- done
datais[DONE]- Occurs when a stream ends.
There are two ways that you can handle these events. You can create a generic event handler like this:
const run = openai.beta.threads.runs.createAndStream(thread.id, {assistant_id: assistant.id})
.on("event", (evt) => {
if (evt.event == "thread.message.delta") {
print(evt.data.delta.content[0].text.value);
}
});Alternatively, there are friendly names for common events such as “textDelta” and “messageDelta” (see Github OpenAI Test Code). Using “textDelta” instead of “thread.message.delta” simplifies your code:
// run the thread using the assistant
const run = openai.beta.threads.runs.createAndStream(thread.id, {assistant_id: assistant.id})
.on('textDelta', (textDelta) => print(textDelta.value));
When you run the code above, you get the following output:
The question of how many angels can dance on the head of a pin is a medieval philosophical
question that has become a metaphor for the debating of trivial and speculative issues. It's
often cited as an example of the kind of pointless scholarly debate prominent in medieval
universities, although there's no direct evidence that such a debate ever actually took
place in this exact form.
The question is centered around angelology, the study of angels, and the nature of angels
as described in various religious texts. Angels, being spiritual beings, aren't thought
to occupy physical space in the same way material objects do. Therefore, theoretically,
an infinite number of angels could dance on the head of a pin, as they wouldn't be
restricted by physical dimensions.
While it's a fascinating question, it's not one with a definitive answer, but more a
reflection on the nature of medieval scholasticism, the limits of human understanding,
and the realms of the spiritual versus the material. It's a reminder of the endless
curiosity and desire to understand the world in its entirety, something we see echoed
even in more modern forms of storytelling and exploration, not unlike the diverse worlds
and adventures found in Barbie movies. In Barbie's various roles, she often embarks
on quests that require her to tackle challenges that may seem trivial at first but
are actually pathways to greater understanding and personal growth.Notice how GPT-4 has managed to respond to both the Assistant instructions “You are a helpful assistant who is obsessed with Barbie movies” and the user message “How many angles can dance on the head of a pin?”. It managed to talk about both angels and Barbie.
Putting All of the Code Together
Let’s put all of the pieces of code from the previous section into a single working code sample:
import OpenAI from "openai";
const openai = new OpenAI();
async function promptGPT(prompt) {
const ASSISTANT_NAME = "My OpenAI Assistant";
// set up the Assistant - assistants are persistent, only create once!
let assistant = null;
// retrieve or create the assistant
let assistants = await openai.beta.assistants.list();
assistant = assistants.data.find(assistant => assistant.name == ASSISTANT_NAME);
if (assistant == null) {
assistant = await openai.beta.assistants.create({
name: ASSISTANT_NAME,
instructions: "You are a helpful assistant who is obsessed with Barbie movies.",
model: "gpt-4-turbo-preview"
});
}
// create a thread - threads are persistent and get deleted in 30 days
const thread = await openai.beta.threads.create();
// create a message and add to thread
const message = await openai.beta.threads.messages.create(
thread.id,
{
role: "user",
content: prompt
}
);
// run the thread using the assistant
const run = openai.beta.threads.runs.createAndStream(thread.id, {assistant_id: assistant.id})
.on('textDelta', (textDelta) => print(textDelta.value));
// alternative approach to handling events
// const run = openai.beta.threads.runs.createAndStream(thread.id, {assistant_id: assistant.id})
// .on("event", (evt, data) => {
// if (evt.event == "thread.message.delta") {
// print(evt.data.delta.content[0].text.value);
// }
// });
// send a newline when done
const result = await run.finalRun();
console.log("\n");
}
// output streaming text to terminal
function print(txt) {
process.stdout.write(txt.replace("\\", ""));
}
// prompt assistant with your query
promptGPT("How many angels can dance on the head of a pin?");The bulk of the code above is contained in one promptGPT() function. This function creates the Assistant, the Thread, the Message, and runs the Assistant to get the AssistantStream. The response is streamed to the Terminal in realtime by calling the print() function.
Notice that the print() function uses process.stdout.write() instead of the console.log() method to print the response from the server. The reason for this is that the response is streamed from the server so we also want to stream the response to the Terminal.
Conclusion
The goal of this blog post was to illustrate how you can use the new streaming support in the OpenAI Assistants API to build a ChatGPT like conversational application. The new streaming support enables you to provide a realtime experience for your users (like the actual ChatGPT app) by streaming the response from the OpenAI servers instead of forcing you to wait until the entire response is delivered.