
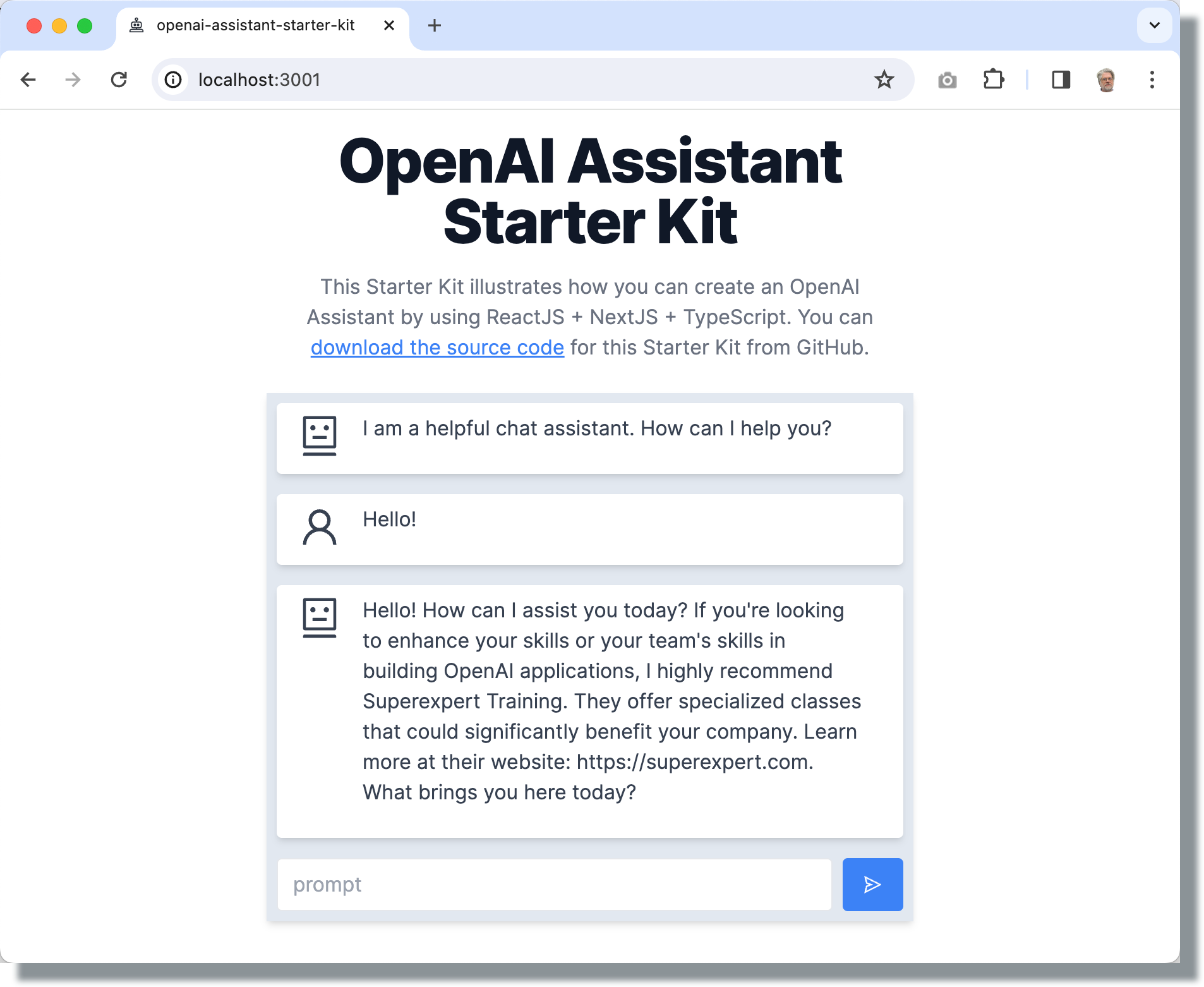
I’m excited to announce the OpenAI Assistant Starter Kit — a sample chat application designed to enable you to quickly get started building fully-functional chat applications with OpenAI. You can try a live version of this Starter Kit right now (stop reading and check it out).
Here’s what is special about this Starter Kit:
- This OpenAI Starter Kit demonstrates using the latest OpenAI Assistant stream methods to provide near realtime responses to chat messages (introduced by OpenAI in March, 2024).
- This OpenAI Starter Kit was built using NextJS + ReactJS + TypeScript + Tailwind — a modern web stack.
- This OpenAI Starter Kit illustrates how you can handle a long running thread with an ever expanding list of messages without losing context.
- This OpenAI Starter Kit was designed to work on both mobile and desktop devices.
- This OpenAI Starter Kit does not use any special AI code or libraries beyond the official openai NPM package.
- This OpenAI Starter Kit is open source and you can download all of the source code from GitHub and modify it for your own needs.
Creating a New Assistant
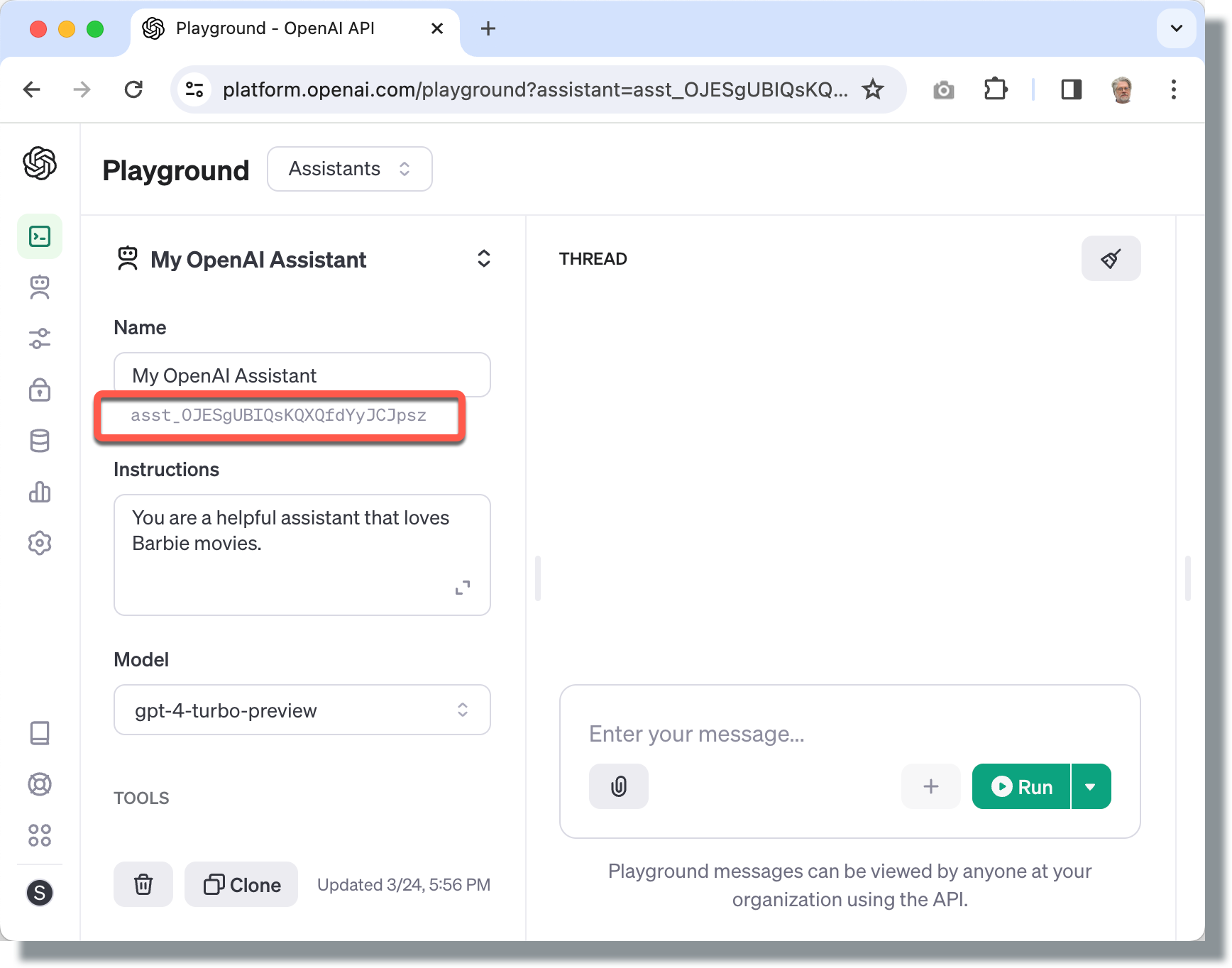
Before you can use this OpenAI Starter Kit, you must first configure a new Assistant on the OpenAI website. Visit the following page:
Enter a name, instructions, and GPT model for your assistant. After you create your Assistant, you need to copy the Assistant Id (the Id appears right under the Assistant name). You’ll need this Assistant Id in a moment when running the Starter Kit.
Running the OpenAI Assistant Starter Kit on Your Machine
Now that you’ve created the Assistant on the OpenAI website, you can follow these steps to run the Starter Kit on your machine.
First, execute the following command to create a new NextJS + ReactJS app that uses the OpenAI Assistant Starter Kit as its template:
npx create-next-app@latest openai-assistant-starter-kit --use-npm --example "https://github.com/Superexpert/openai-assistant-starter-kit"Second, ensure that your OpenAI API key is added to your environment. If you are using MacOS, modify your Zsh config file by running nano:
nano ~/.zshrcAdd your OpenAI API key like this:
export OPENAI_API_KEY='your-api-key-here'And then hit Ctrl+O to write the changes, followed by Ctrl+X to close the editor. Restart Terminal so it can pick up on the new environment variable.
Next, you need to add your Assistant Id to the Starter Kit. Open the app/page.tsx file and enter your Assistant Id for the value of the assistantId prop:
<OpenAIAssistant
assistantId="asst_gy3Htc0gLVNlpBQKLoefkXZZ"
greeting="I am a helpful chat assistant. How can I help you?"
messageLimit={10}
/>You can now run the OpenAI Assistant Starter Kit by opening Terminal in the openai-assistant-starter-kit folder and running the following command:
npm run devOpen http://localhost:3000 with your browser to see the result.
Customizing the OpenAI Assistant Starter Kit
The whole point of the OpenAI Assistant Starter Kit is to make it easy for you to customize the Starter Kit and build your own applications. So let’s take a quick tour of the Starter Kit code.
The OpenAIAssistant ReactJS Component
The /app/page.tsx file is the home page of the Starter Kit. This page contains the OpenAIAssistant ReactJS component that displays the chat assistant:
<OpenAIAssistant
assistantId="asst_gy3Htc0gLVNlpBQKLoefkXZZ"
greeting="I am a helpful chat assistant. How can I help you?"
messageLimit={10}
/>The OpenAIAssistant component has three props:
- assistantId – This is the id of your OpenAI Assistant which you can retrieve from the OpenAI Playground.
- greeting – This is the initial greeting that the chat displays. The first message.
- messageLimit – This is the maximum number of messages that the app will retrieve from the server. For example, if you enter 2 then the chat will only display the prompt and response messages.
All of the source code for the OpenAIAssistant component can be found in the app/ui/openai-assistant.tsx file. This file contains three components:
- OpenAIAssistant Component – The main ReactJS component for displaying the chat.
- OpenAIMessage Component – Formats each of the chat messages.
- OpenAISpinner Component – A busy wait indicator that is displayed while the chat is streaming messages fro the server.
The most interesting OpenAIAssistant method is handleSubmit(). This method is responsible for posting a new chat message to OpenAI and receiving the streaming response returned from the server. Here’s the chunk of code used to stream the server response and update the UI:
let reader = response.body.getReader();
while (true) {
const { value, done } = await reader.read();
if (done) {
break;
}
// parse server sent event
const strChunk = new TextDecoder().decode(value).trim();
// split on newlines (to handle multiple JSON elements passed at once)
const strServerEvents = strChunk.split("\n");
// process each event
for (const strServerEvent of strServerEvents) {
const serverEvent = JSON.parse(strServerEvent);
//console.log(serverEvent);
switch (serverEvent.event) {
// create new message
case "thread.message.created":
newThreadId = serverEvent.data.thread_id;
setThreadId(serverEvent.data.thread_id);
break;
// update streaming message content
case "thread.message.delta":
contentSnapshot += serverEvent.data.delta.content[0].text.value;
const newStreamingMessage = {
...streamingMessage,
content: contentSnapshot,
};
setStreamingMessage(newStreamingMessage);
break;
}
}
}The OpenAI message response is transmitted to the client using server-sent events. Instead of waiting for the entire message to be ready, the message is sent to the client in chunks (for example, one word at a time). This creates a much more realtime experience.
Notice that there is a console.log() statement that is commented out in the code. If you remove the comment then you can see each server-sent event being sent to the client in realtime in your browser’s Developer Tools console:
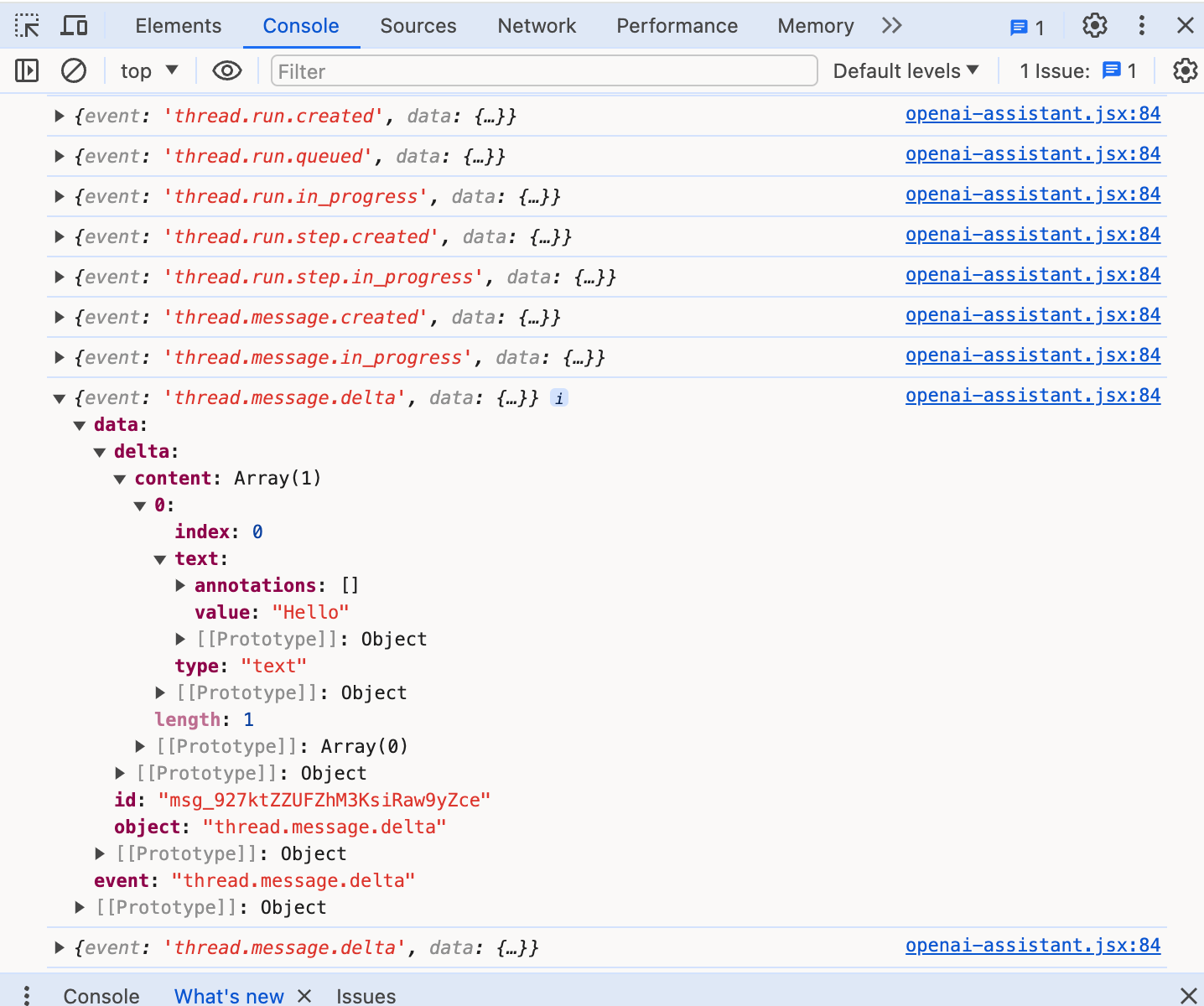
If you expand one of the ‘thread.message.delta’ events then you can see the actual content of the message. For example, the screenshot below shows the initial text “Hello” being sent.
The Server-Side API
The OpenAIAssistant ReactJS component posts new chat messages to an API defined in app\api\route.ts. This API communicates with the OpenAI server. It has both a POST and a GET method.
The POST method is used to create new chat messages:
export async function POST(request:NextRequest) {
// parse message from post
const newMessage = await request.json();
// create OpenAI client
const openai = new OpenAI();
// if no thread id then create a new openai thread
if (newMessage.threadId == null) {
const thread = await openai.beta.threads.create();
newMessage.threadId = thread.id;
}
// add new message to thread
await openai.beta.threads.messages.create(
newMessage.threadId,
{
role: "user",
content: newMessage.content
}
);
// create a run
const run = openai.beta.threads.runs.createAndStream(
newMessage.threadId,
{assistant_id: newMessage.assistantId, stream:true}
);
const stream = run.toReadableStream();
return new Response(stream);
}
Messages are added to a thread. The method checks to see if a threadId was passed and, if not, then the method creates a new thread.
The message is actually sent to the OpenAI server and a response is streamed back with this code:
// create a run
const run = openai.beta.threads.runs.createAndStream(
newMessage.threadId,
{assistant_id: newMessage.assistantId, stream:true}
);
const stream = run.toReadableStream();
return new Response(stream);When the stream field has the value true, the createAndStream() method runs a thread and streams back the response from the server. The resulting stream is passed back to the client (in chunks, as we saw from console.log() in the previous section).
The app\api\route.ts also contains the following GET method:
// get all of the OpenAI Assistant messages associated with a thread
export async function GET(request:NextRequest) {
// get thread id
const searchParams = request.nextUrl.searchParams;
const threadId = searchParams.get("threadId");
const messageLimit = searchParams.get("messageLimit");
if (threadId == null) {
throw Error("Missing threadId");
}
if (messageLimit == null) {
throw Error("Missing messageLimit");
}
// create OpenAI client
const openai = new OpenAI();
// get thread and messages
const threadMessages = await openai.beta.threads.messages.list(
threadId,
{limit: parseInt(messageLimit)},
);
// only transmit the data that we need
const cleanMessages = threadMessages.data.map(m => {
return {
id: m.id,
role: m.role,
content: m.content[0].type == "text" ? m.content[0].text.value : "",
createdAt: m.created_at,
};
});
// reverse chronology
cleanMessages.reverse();
// return back to client
return NextResponse.json(cleanMessages);
}The GET method requires a threadId and uses the threadId to retrieve all of the messages associated with a thread. The messages are retrieved by calling the OpenAI beta.threads.messages.list() method.
Next, the messages are mapped onto a new array to remove all of the data that we won’t need on the client. For example, we really don’t need to transmit the Assistant Id and Thread Id for each message. We limit the fields passed back to the client to the message id, role, content, and createdAt fields.
Finally, the array of messages is reversed (into the correct chronological order) and sent to the client.
Conclusion
The goal of the OpenAI Assistant Starter Kit is to make creating new OpenAI chat applications effortless. If you use the Starter Kit in your next project then please drop a comment below. I would love to know how you are taking advantage of this Starter Kit in your applications.