
The goal of this blog post is to explain how you are charged when you call OpenAI APIs. In particular, the focus of this post is explaining OpenAI API costs when you are interacting with OpenAI Large Language Models such as ChatGPT-4.
The short answer is that OpenAI charges you per word. Like a pulp fiction novelist, ChatGPT is paid by the word. Or, more accurately, you are charged for each token that you pass to OpenAI and that OpenAI returns to you.
You can view OpenAI’s current pricing by visiting the following page:
For example, OpenAI charges you $10 dollars for every million tokens that you pass to GPT-4 Turbo and $30 for every million tokens that GPT-4 Turbo returns. Different models — such as GPT-4 Turbo, GPT-4, and GPT-3.5 Turbo — have different per token costs. GPT-3 Turbo only costs a fraction of GPT-4 Turbo ($0.50 per million tokens passed to the model and $1.50 per million tokens passed back). The smarter the model, the more you pay.
You can navigate to https://platform.openai.com/usage to see the actual amount that you are paying to call the OpenAI APIs:

But What is a Token?
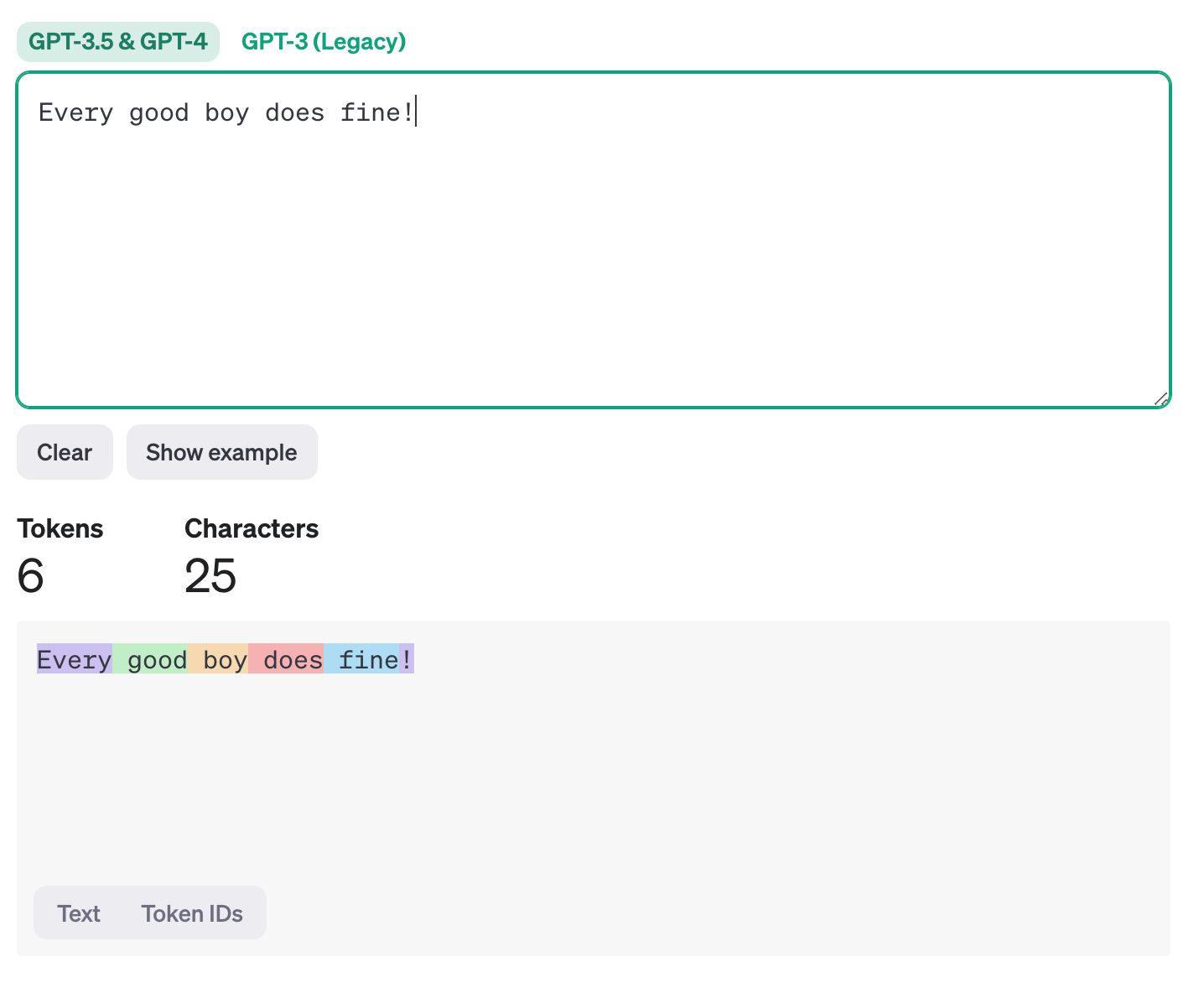
A token is not the same thing as a word. When you pass a string of text to an OpenAI API (such as the Chat Completions API) the string of text is broken into tokens. You can use the following tool provided by OpenAI to see how a string of text is converted into tokens:
https://platform.openai.com/tokenizer
For example, entering the sentence “Every good boy does fine!” results in 6 tokens. Notice that the exclamation mark (“!”) counts as its own token.
In general, 75 words correspond to approximately 100 tokens. But this is inexact because words are broken into tokens in different ways. Some examples:
- “My honor impels me to challenge you to a duel.” — this sentence results in 12 tokens because “impels” is counted as two tokens.
- “Dorothy lived in the midst of the great Kansas prairies, with Uncle Henry, who was a farmer, and Aunt Em, who was the farmer’s wife.” — this sentence results in 32 tokens because “Dorothy” is broken into 3 distinct tokens and “prairies” is also broken into 3 distinct tokens. This means that talking about Dorothy with ChatGPT is three times more expensive than talking about Harry (weird).
Calculating the Number of Tokens Used in an API Call
When calling the Chat Completions API, you can look at the usage field to return the actual number of tokens passed to the method and returned by the method. Here is a code sample using NodeJS:
import OpenAI from "openai";
const openai = new OpenAI();
async function main() {
const completion = await openai.chat.completions.create({
messages: [{ role: "system", content: "You are a helpful assistant. But you are obsessed with the Barbie movie." }],
model: "gpt-3.5-turbo",
});
// write completion message
console.log(completion.choices[0].message);
// print prompt_tokens, completion_tokens, and total_tokens
console.log(completion.usage);
}
main();The code above calls the OpenAI Chat Completions API with the message “You are a helpful assistant. But you are obsessed with the Barbie movie.” The model might return different responses. When I ran the code, I received the response: “Hello, there! Are you ready for a fabulous adventure? I’m here to assist you with anything you need, just like the characters in the Barbie movies always help each other out. If you have any questions or need assistance, just let me know!”
Notice the following line of code:
// print prompt_tokens, completion_tokens, and total_tokens
console.log(completion.usage);The completion usage field returns the number of tokens passed to the model (prompt_tokens) and the number of tokens returned from the model (completion_tokens) and the total (total_tokens). In this case, the exchange resulted in 73 total_tokens:
- “You are a helpful assistant. But you are obsessed with the Barbie movie.” = 22 prompt_tokens
- “Hello, there! Are you ready for a fabulous adventure? I’m here to assist you with anything you need, just like the characters in the Barbie movies always help each other out. If you have any questions or need assistance, just let me know!” = 51 completion_tokens.
But, wait a minute! If you compare the number of prompt_tokens counted by the usage field and the tokenizer tool then you get a different result:
| Message | usage tokens | tokenizer tokens |
| “You are a helpful assistant. But you are obsessed with the Barbie movie.” | 22 | 15 |
| “Hello, there! Are you ready for a fabulous adventure? I’m here to assist you with anything you need, just like the characters in the Barbie movies always help each other out. If you have any questions or need assistance, just let me know!” | 51 | 51 |
Is this how Sam Altman became a billionaire? Where are these 7 additional tokens coming from? The answer is that OpenAI needs additional tokens for each message and the reply. In particular, when using GPT-3.5 Turbo, OpenAI adds 4 tokens for each message and 3 tokens for the reply for a total of 7 additional tokens (see this article).
Remember, a Long Conversation Has More and More Messages
Conversations drive up the OpenAI API costs. One thing to keep in mind is that, typically, you are passing all of the previous messages back to OpenAI when you are create a conversation. In other words, for each new message, you pay the price for all of the previous messages.
The following code enables you to engage in a conversation with ChatGPT:
import OpenAI from "openai";
import promptSync from 'prompt-sync';
const prompt = promptSync({sigint:1});
const openai = new OpenAI();
// initial system message
const messages = [{
"role": "system",
"content": "You are a helpful assistant who loves the color orange."
}];
// call the AI
async function promptGPT() {
const response = await openai.chat.completions.create({
model: "gpt-3.5-turbo",
messages: messages,
});
return response;
}
// loop forever (hit CTRL-c to stop)
while (1==1) {
// prompt the user
let ask = prompt(">>> ");
// store the user message in messages
messages.push({
role: "user",
content: ask,
});
// call ChatGPT
let responseGPT = await promptGPT();
let message = responseGPT.choices[0].message;
// store the ChatGPT response in messages
messages.push(message);
// show all of the messages
console.log(messages);
// show usage
console.log(responseGPT.usage);
}Here’s what a conversation looks like when running the code above:
>>> Hello
[
{
role: 'system',
content: 'You are a helpful assistant who loves the color orange.'
},
{ role: 'user', content: 'Hello' },
{
role: 'assistant',
content: "Hello! I'm here to assist you. What can I help you with today?"
}
]
{ prompt_tokens: 23, completion_tokens: 17, total_tokens: 40 }
>>> What is your favorite color?
[
{
role: 'system',
content: 'You are a helpful assistant who loves the color orange.'
},
{ role: 'user', content: 'Hello' },
{
role: 'assistant',
content: "Hello! I'm here to assist you. What can I help you with today?"
},
{ role: 'user', content: 'What is your favorite color?' },
{
role: 'assistant',
content: 'My favorite color is orange! I just love how vibrant and energetic it is. How about you, do you have a favorite color?'
}
]
{ prompt_tokens: 54, completion_tokens: 27, total_tokens: 81 }
>>> I do not like orange. I like the color blue.
[
{
role: 'system',
content: 'You are a helpful assistant who loves the color orange.'
},
{ role: 'user', content: 'Hello' },
{
role: 'assistant',
content: "Hello! I'm here to assist you. What can I help you with today?"
},
{ role: 'user', content: 'What is your favorite color?' },
{
role: 'assistant',
content: 'My favorite color is orange! I just love how vibrant and energetic it is. How about you, do you have a favorite color?'
},
{
role: 'user',
content: 'I do not like orange. I like the color blue.'
},
{
role: 'assistant',
content: "That's totally okay! Blue is a beautiful and calming color as well. It's great that we all have different preferences when it comes to colors. If you have any questions or need assistance with anything related to blue or anything else, feel free to ask!"
}
]
{ prompt_tokens: 101, completion_tokens: 52, total_tokens: 153 }Notice that the number of messages passed to ChatGPT keeps increasing and the prompt_tokens (and total_tokens) keeps getting bigger: 40 to 81 to 153 total tokens. The longer the conversation, the more expensive it gets.
Can I Limit the Number of Tokens that I Use?
You can limit the number of tokens that OpenAI generates by taking advantage of the max_completions field. This field limits the number of completion_tokens (the tokens returned by calling ChatGPT). Here is a code sample:
import OpenAI from "openai";
const openai = new OpenAI();
async function main() {
const completion = await openai.chat.completions.create({
messages: [{ role: "system", content: "You are a helpful assistant. But you are obsessed with the Barbie movie." }],
model: "gpt-3.5-turbo",
max_tokens: 5,
});
// write completion message
console.log(completion.choices[0].message);
// print prompt_tokens, completion_tokens, and total_tokens
console.log(completion.usage);
}
main();In the code above, max_tokens is set to the value 5. The Chat Completions API will return no more than 5 tokens. For example, when I run the code above, I get “Hello there! I’m” which is exactly 5 tokens. Notice that this sentence is cut off to ensure that only 5 characters are returned. The Large Language Model does not take into account the max_tokens when generating its answer so it is like interrupting the AI mid sentence.
What is the value of max_tokens if you do not specify a value? For GPT-3.5 and later, if you don’t specify a value, then the only limit for the total number of tokens in a response is the total context window for a model (see model context windows). For example, ChatGPT-4 Turbo has a context window of 128,000 tokens. That means that the total tokens (prompt_tokens + completion_tokens) cannot ever be greater than 128,000.
Conclusion
The goal of this blog post was to clarify how OpenAI pricing works and how you can keep your OpenAI API costs down. To address that question, we had to dive into the topic of tokens because, when you use ChatGPT models, you are charged by the token. You learned how to take advantage of the usage field to determine the actual number of tokens used for an OpenAI API request. You were also warned that the number of tokens grows quickly when you engage in a conversation with ChatGPT because all of the previous messages must be sent again.